MNIST GAN(Generative Adversarial Network)
GANは敵対学習と呼ばれる2014年頃に提案された生成モデリングの一種の手法である。
GANはGenerator(生成モデル)とDiscriminator(識別モデル)の2つのニューラルネットワークのモデルを持つ。
Generatorは訓練データと近いデータを生成できるように教師なしで学習する。反対にDiscriminatorは与えられた入力が訓練データ(本物)か、Generatorが生成したデータ(偽物)かを識別できるように学習する。このように2つのモデルの精度の関係はトレードオフである。
GANはこの2つのモデルを同時に学習し、最終的にはGeneratorが訓練データと近いデータを生成できるように学習し、その時Discriminatorの予測としては本物よ偽物の見分けがつかない、すなわち確率として曖昧な50%といった値を返すようになるのが理想である。
GANの構造
GANが持つ両モデルはニューラルネットワークで構築される。
ここではマルチパーセプトロン(MLP)を用いる
MNISTの手書き数字の画像(28*28)を訓練データとして使用するとしてGeneratorのネットワークは次のようになる
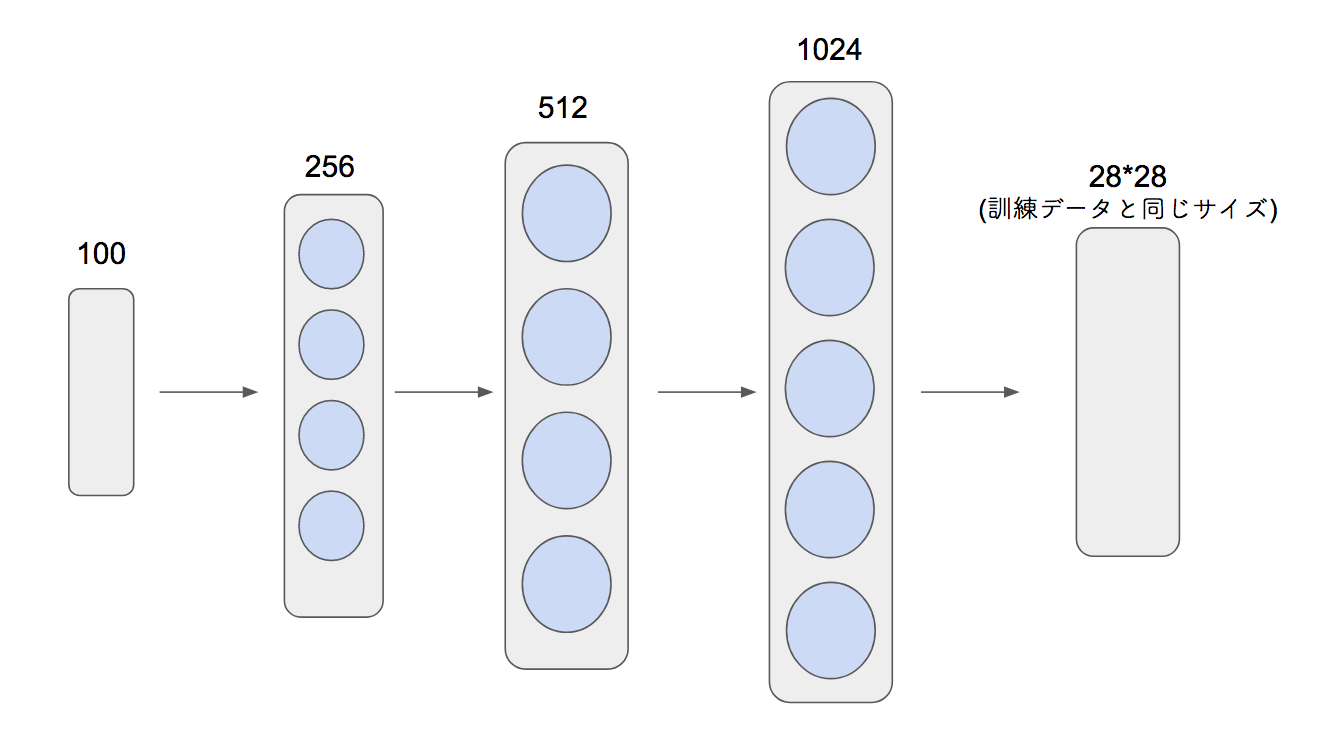
Generatorの入力は100次元ベクトルで、閉区間[-1,1]の一様分布に従うものからランダムに取ってくる。
Discriminatorのネットワークは次のようになる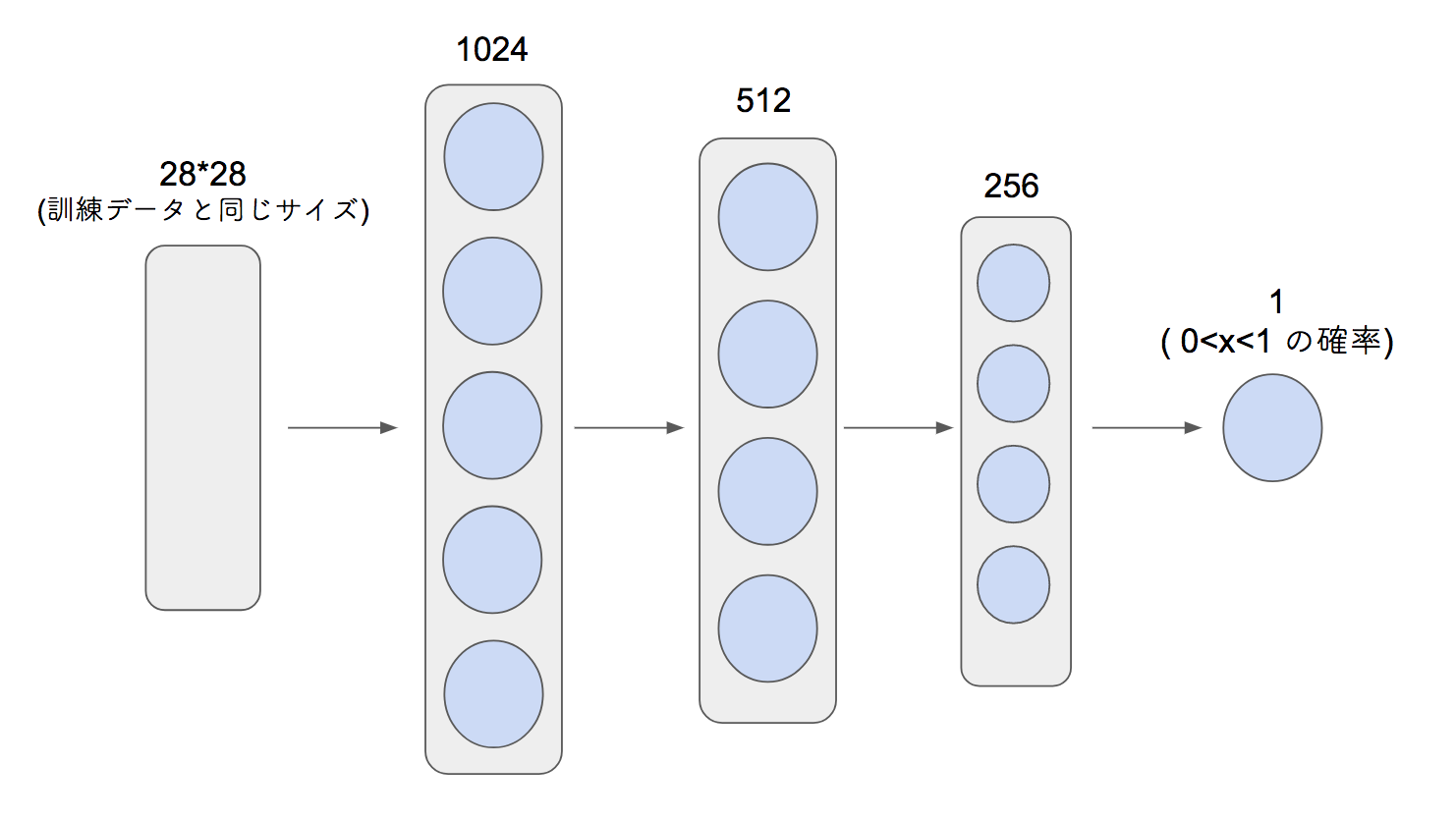
Discriminatorの出力はシグモイド関数を使って活性化し、0 <= x <= 1の確率(偽物か本物か)として出力を得る。
ここでは値が1に近いほど本物であるとする。
GANの目的関数
Generatorの目的関数は次のように定義される
mはミニバッチサイズを表している。θgは学習係数である。この式が最小の値を取るようにGeneratorが持つパラメータを確率勾配法を用いて更新していく。そのためlogD(G(z))のD(G(z))が1を取るようにする。すなわちDiscriminatorにGeneratorが生成したデータを渡した時に本物と多く識別されるようにする。
Discriminatorの目的関数は次のように定義される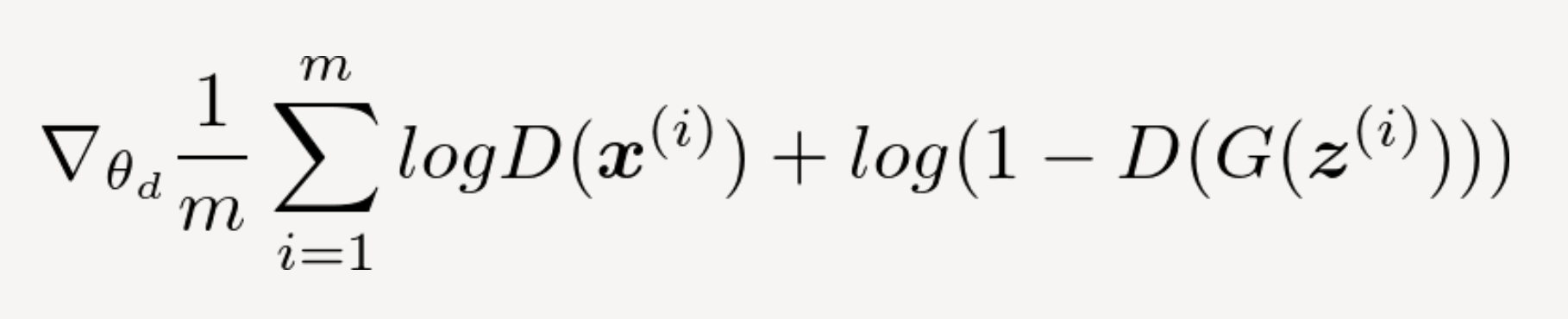
θdは学習係数である。第一項のlogD(x)は訓練データを渡しており、本物 = 1 を割り当てるように、第二項のlogD(G(z))は 偽物 = 0を割り当てるように識別する。この式が最小の値をとるようにDiscriminatorが持つパラメータを確率勾配法を用いて更新していく。
Tensorflowを用いたGANの実装
Generatorの実装
class Generator():
def __init__(self,device_name='/cpu:0'):
# Generator parameter
with tf.device(device_name):
self.gen_w1 = tf.Variable(tf.truncated_normal(shape=[100,256],stddev=0.02,dtype=tf.float32),name="gen_w1")
self.gen_b1 = tf.Variable(tf.truncated_normal(shape=[256],stddev=0.02,dtype=tf.float32),name="gen_b1")
self.gen_w2 = tf.Variable(tf.truncated_normal([256,512],stddev=0.02,dtype=tf.float32),name="gen_w2")
self.gen_b2 = tf.Variable(tf.truncated_normal(shape=[512],stddev=0.02,dtype=tf.float32),name="gen_b2")
self.gen_w3 = tf.Variable(tf.truncated_normal([512,1024],stddev=0.02,dtype=tf.float32),name="gen_w3")
self.gen_b3 = tf.Variable(tf.truncated_normal(shape=[1024],stddev=0.02,dtype=tf.float32),name="gen_b3")
self.gen_w4 = tf.Variable(tf.truncated_normal([1024,28*28],stddev=0.02,dtype=tf.float32),name="gen_w4")
self.gen_b4 = tf.Variable(tf.truncated_normal(shape=[28*28],stddev=0.02,dtype=tf.float32),name="gen_b4")
self.gen_scale_w1 = tf.Variable(tf.ones([256]),name="gen_scale_w1")
self.gen_offset_w1 = tf.Variable(tf.zeros([256]),name="gen_offset_w1")
self.gen_scale_w2 = tf.Variable(tf.ones([512]),name="gen_scale_w2")
self.gen_offset_w2 = tf.Variable(tf.zeros([512]),name="gen_offset_w2")
self.gen_scale_w3 = tf.Variable(tf.ones([1024]),name="gen_scale_w3")
self.gen_offset_w3 = tf.Variable(tf.zeros([1024]),name="gen_offset_w3")
self.keep_prob = tf.placeholder(tf.float32)
def run(self,z,is_train,device_name='/cpu:0'):
with tf.device(device_name):
h1 = tf.nn.leaky_relu(tf.nn.xw_plus_b(z,self.gen_w1,self.gen_b1),alpha=0.2)
h1 = batch_norm(h1,self.gen_scale_w1,self.gen_offset_w1,[0],is_train,device_name)
h2 = tf.nn.leaky_relu(tf.nn.xw_plus_b(h1,self.gen_w2,self.gen_b2),alpha=0.2)
h2 = batch_norm(h2,self.gen_scale_w2,self.gen_offset_w2,[0],is_train,device_name)
h3 = tf.nn.leaky_relu(tf.nn.xw_plus_b(h2,self.gen_w3,self.gen_b3),alpha=0.2)
h3 = batch_norm(h3,self.gen_scale_w3,self.gen_offset_w3,[0],is_train,device_name)
h3_drop = tf.nn.dropout(h3, self.keep_prob)
fc = tf.nn.sigmoid(tf.nn.xw_plus_b(h3_drop,self.gen_w4,self.gen_b4))
run()でネットワークを定義している。中間層の活性化関数としてleaky_relu関数を適用する。ハイパーパラメータとしてalpha=0.2を採用する。またバッチ正規化(Batch normalization)も適用する。
注意点として、Generatorの各パラメータにDiscriminatorと区別がつくようにname="gen_~"といった名前をつけておくこと。(パラメータの更新時に必要)
Discriminator
class Discrimitor():
def __init__(self,device_name='/cpu:0'):
# Discrimitor parameter
with tf.device(device_name):
self.dis_w1 = tf.Variable(tf.truncated_normal([28*28,1024],stddev=0.02,dtype=tf.float32),name="dis_w1")
self.dis_b1 = tf.Variable(tf.truncated_normal([1024],stddev=0.02,dtype=tf.float32),name="dis_b1")
self.dis_w2 = tf.Variable(tf.truncated_normal([1024,512],stddev=0.02,dtype=tf.float32),name="dis_w2")
self.dis_b2 = tf.Variable(tf.truncated_normal([512],stddev=0.02,dtype=tf.float32),name="dis_b2")
self.dis_w3 = tf.Variable(tf.truncated_normal([512,256],stddev=0.02,dtype=tf.float32),name="dis_w3")
self.dis_b3 = tf.Variable(tf.truncated_normal([256],stddev=0.02,dtype=tf.float32),name="dis_b3")
self.dis_w4 = tf.Variable(tf.truncated_normal([256,1],stddev=0.02,dtype=tf.float32),name="dis_w4")
self.dis_b4 = tf.Variable(tf.truncated_normal([1],stddev=0.02,dtype=tf.float32),name="dis_b4")
def run(self,x,device_name='/cpu:0'):
with tf.device(device_name):
h1 = tf.nn.leaky_relu(tf.nn.xw_plus_b(x,self.dis_w1,self.dis_b1),alpha=0.2)
h2 = tf.nn.leaky_relu(tf.nn.xw_plus_b(h1,self.dis_w2,self.dis_b2),alpha=0.2)
h3 = tf.nn.leaky_relu(tf.nn.xw_plus_b(h2,self.dis_w3,self.dis_b3),alpha=0.2)
fc = tf.nn.sigmoid(tf.nn.xw_plus_b(h3,self.dis_w4,self.dis_b4))
return fc
Discrimitorにはバッチ正規化を適用しない。
こちらもGeneratorと区別がつくように各パラメータに名前をつけておくこと。
GAN
class GAN():
def __init__(self,using_gpu):
self.device_name = '/cpu:0'
if(using_gpu):
self.device_name = '/gpu:0'
print('using : {}'.format(self.device_name))
with tf.device(self.device_name):
# GeneratorのBatchnormに必要
self.is_train = tf.placeholder(tf.bool)
# t0は0のラベルを格納し、t1は1のラベルを格納する
self.label_t0 = tf.placeholder(tf.float32, shape=(None,1))
self.label_t1 = tf.placeholder(tf.float32, shape=(None,1))
# Generator
self.generator = Generator(device_name=self.device_name)
# 生成モデルに必要なノイズの入れ物
self.gen_z = tf.placeholder(tf.float32, shape=(None,100))
# Discrimitor
self.discrimitor = Discrimitor(device_name=self.device_name)
# Discriminatorの入力の入れ物
self.input_X = tf.placeholder(tf.float32, shape=(None,28*28))
# 訓練データの識別予測結果
input_X = self.discrimitor.run(self.input_X,device_name=self.device_name)
# 生成されたデータの識別予測結果
generated_X = self.discrimitor.run(self.generator.run(z=self.gen_z,is_train=self.is_train,device_name=self.device_name))
self.dis_entropy_X = tf.nn.sigmoid_cross_entropy_with_logits(labels=self.label_t1, logits=input_X)
self.dis_entropy_G = tf.nn.sigmoid_cross_entropy_with_logits(labels=self.label_t0, logits=generated_X)
# Discriminatorの目的関数
self.dis_loss = tf.reduce_mean(self.dis_entropy_X + self.dis_entropy_G)
self.gen_entropy = tf.nn.sigmoid_cross_entropy_with_logits(labels=self.label_t1,logits=generated_X)
# Generatorの目的関数
self.gen_loss = tf.reduce_mean(self.gen_entropy)
# 最適化する際にDならDのみのパラメータを、GならGのみのパラメータを更新するようにしたいのでモデル別の変数を取得する
dis_vars = [x for x in tf.trainable_variables() if "dis_" in x.name]
gen_vars = [x for x in tf.trainable_variables() if "gen_" in x.name]
# 識別モデルDの最適化
self.opt_d = tf.train.AdamOptimizer(0.0002, beta1=0.1).minimize(self.dis_loss,var_list=[dis_vars])
# 生成モデルGの最適化
self.opt_g = tf.train.AdamOptimizer(0.0002, beta1=0.5).minimize(self.gen_loss,var_list=[gen_vars])
ここで
dis_vars = [x for x in tf.trainable_variables() if "dis_" in x.name]
gen_vars = [x for x in tf.trainable_variables() if "gen_" in x.name]
と定義しているのは、Generatorではパラメータの更新においてDiscriminatorを経由しておりself.opt_gの引数var_list=[gen_vars]といった更新するパラメータを指定しないとGeneratorのパラメータのみを更新したいのにDiscriminatorのパラメータまで更新してしまうからである。
このときDiscriminatorはGeneratorから生成されたデータに対して本物と識別するようにパラメータを更新してしまうので学習が良い方向に進まなくなってしまう。
Discrimitorのパラメータ更新においてもGeneratorを経由しているので、同様のことが起こる。そのため前で述べたように各パラメータに区別がつくように名前をつけておく必要がある。
次にGANのクラスに次の関数を追加する
def train(self
, X_train = None
, batch_size = 100
, epoch_num = 1000
, imgpath = './mnist_GAN_images/'
, ckptpath = './mnist_GAN_checkpoints/'
, log_file='mnist_GAN_loss_log.csv'
, init = False):
if X_train is None:
raise TypeError("X_train is None")
# 訓練途中で生成データを作成して保存したいのでその保存先の作成
p = Path(imgpath)
if not(p.is_dir()):
p.mkdir()
# モデルパラメータのチェックポイントの保存先
ckpt_p = Path(ckptpath)
if not(ckpt_p.is_dir()):
ckpt_p.mkdir()
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
saver = tf.train.Saver()
sess = tf.Session()
if(init):
sess.run(tf.global_variables_initializer())
print('Initialize')
ckpt = tf.train.get_checkpoint_state(str(ckpt_p.absolute()))
if ckpt:
# checkpointファイルから最後に保存したモデルへのパスを取得する
last_model = ckpt.model_checkpoint_path
print("load {0}".format(last_model))
# 学習済みモデルを読み込む
saver.restore(sess, last_model)
step = len(X_train) // batch_size
# 正解ラベルのミニバッチ
t1_batch = np.ones((batch_size,1),dtype=np.float32)
t0_batch = np.zeros((batch_size,1),dtype=np.float32)
for epoch in range(epoch_num):
#各エポックごとに訓練データをシャッフルする
perm = np.random.permutation(len(X_train))
# 1エポックごとにかかる時間の計測
start = time.time()
for k in range(step):
X_batch = X_train[perm][k*batch_size:(k+1)*batch_size]
# Train Discrimitor
# ノイズ事前分布からノイズをミニバッチ分取得
noise_z = np.random.uniform(-1,1, size=[batch_size, 100]).astype(np.float32)
sess.run(self.opt_d, feed_dict = {self.input_X:X_batch
, self.is_train:False
, self.gen_z:noise_z
, self.generator.keep_prob:1.0
, self.label_t1:t1_batch
, self.label_t0:t0_batch})
if k % 1 == 0:
# Train Generator
# ノイズ事前分布からノイズをミニバッチ分取得
noise_z = np.random.uniform(-1,1, size=[batch_size, 100]).astype(np.float32)
sess.run(self.opt_g, feed_dict = {self.gen_z:noise_z
, self.is_train:True
, self.generator.keep_prob:0.5
, self.label_t1:t1_batch})
# 1epoch終了時の損失を表示
noise_z = np.random.uniform(-1,1, size=[batch_size, 100]).astype(np.float32)
train_dis_loss = sess.run(self.dis_loss, feed_dict = {self.input_X:X_batch
, self.is_train:False
, self.gen_z:noise_z
, self.generator.keep_prob:1.0
, self.label_t1:t1_batch
, self.label_t0:t0_batch})
train_gen_loss = sess.run(self.gen_loss, feed_dict ={self.gen_z:noise_z
, self.is_train:False
, self.generator.keep_prob:1.0
, self.label_t1:t1_batch})
print("[Train] epoch: %d, dis loss: %f , gen loss : %f Time : %f" % (epoch, train_dis_loss, train_gen_loss, time.time() - start))
saver.save(sess, str(ckpt_p.absolute())+'/GAN-mnist')
# lossの記録
f = open(log_file, 'a')
log_writer = csv.writer(f, lineterminator='\n')
loss_list = []
loss_list.append(epoch)
loss_list.append(train_dis_loss)
loss_list.append(train_gen_loss)
# 損失の値を書き込む
log_writer.writerow(loss_list)
f.close()
# 10epoch終了毎に生成モデルから5枚の画像を生成する
if epoch % 10 == 0:
noise_z = np.random.uniform(-1,1, size=[5, 100]).astype(np.float32)
z_const = tf.constant(noise_z,dtype=tf.float32)
gen_imgs = sess.run(self.generator.run(z_const, is_train=False),feed_dict={self.generator.keep_prob:1.0}) * 255.
for i,img in enumerate(gen_imgs):
Image.fromarray(img.reshape(28,28)).convert('RGB').save(
str(p.absolute())+'/generate_img_epoch{0}_{1}.jpg'.format(epoch, i)
)
GPUを用いて学習を行う際は訓練する前に
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
model = GAN(using_gpu=True)
とすること。使用しない場合はmodel = GAN(using_gpu=False)のみで問題ない
学習
X_train = np.r_[dataset.train.images]
model = GAN(using_gpu=True)
model.train(
X_train=X_train,
batch_size=100,
epoch_num=71,
init=True,
ckptpath='./mnist_GAN_checkpoints_adam_gpu/',
imgpath='./mnist_GAN_images_gpu/')
batch_sizeやepoch_numは任意変更
MNISTの全訓練データ(55000件)を用いて70epochまでの学習で生成された結果物
Notebook
https://github.com/FaBoPlatform/TensorFlow/blob/master/notebooks/GAN_mnist.ipynb